
Das wichtigste auf einen Blick:
- Ein Data Warehouse ist stark für kuratierte, strukturierte und wiederkehrend genutzte Daten: BI, Reporting, Controlling, Management-Kennzahlen.
- Ein Data Lake ist stark für rohnähere, vielfältige und noch nicht vollständig modellierte Daten: Sensorik, Logs, Zeitreihen, Dokumente, Machine Learning, Exploration.
- Ein Data Lakehouse kombiniert Eigenschaften von Warehouse und Lake, ist aber keine automatische Bestlösung.
- BI-ready ist nicht automatisch AI-ready: Reporting-Daten reichen für KI-Use-Cases oft nicht aus.
- Ein Data Lake ohne Metadaten, Data Catalog, Ownership, Zugriffskontrolle und Qualitätsregeln wird schnell zum Data Swamp.
- Die bessere Entscheidungslogik lautet: Use Case zuerst, Datenqualität und Governance danach, Speicherarchitektur zuletzt.
Im ERP stehen Aufträge. Im MES stehen Produktionsdaten. Im WMS stehen Bestände. Im Controlling entstehen Excel-Reports. Sensorik erzeugt Zeitreihen. BI zeigt Kennzahlen. Und jetzt soll daraus auch noch eine belastbare KI-Grundlage werden.
An diesem Punkt wirkt die Frage naheliegend: Data Warehouse oder Data Lake?
Sie ist wichtig. Aber sie ist selten die beste Startfrage. Denn die entscheidenden Unterschiede liegen weniger im Namen als im Einsatzkontext.
Für mittelständische Industrie-, Maschinenbau- und Logistikunternehmen entscheidet nicht der modernste Speicherbegriff über den Nutzen einer Datenarchitektur. Entscheidend ist, welche Daten für welchen Prozess, welche Entscheidung und welchen KI-Use-Case in welcher Qualität kontrolliert nutzbar werden.
Ein Data Warehouse kann verlässliche Kennzahlen schaffen. Ein Data Lake kann vielfältige Rohdaten für Analyse und KI zugänglich machen. Ein Lakehouse kann beide Welten technisch näher zusammenführen. Aber keine dieser Architekturen ersetzt die eigentliche Managementarbeit: Datenqualität, Governance, Verantwortlichkeiten, Integration und messbare Wirkung.
Kurzantwort: Was ist der Unterschied zwischen Data Warehouse und Data Lake?
Ein Data Warehouse speichert in der Regel bereinigte, modellierte und fachlich kuratierte Daten für Business Intelligence, Reporting und wiederkehrende Analysen. Es ist stark, wenn Kennzahlen verlässlich, konsistent und für Fachbereiche verständlich sein müssen.
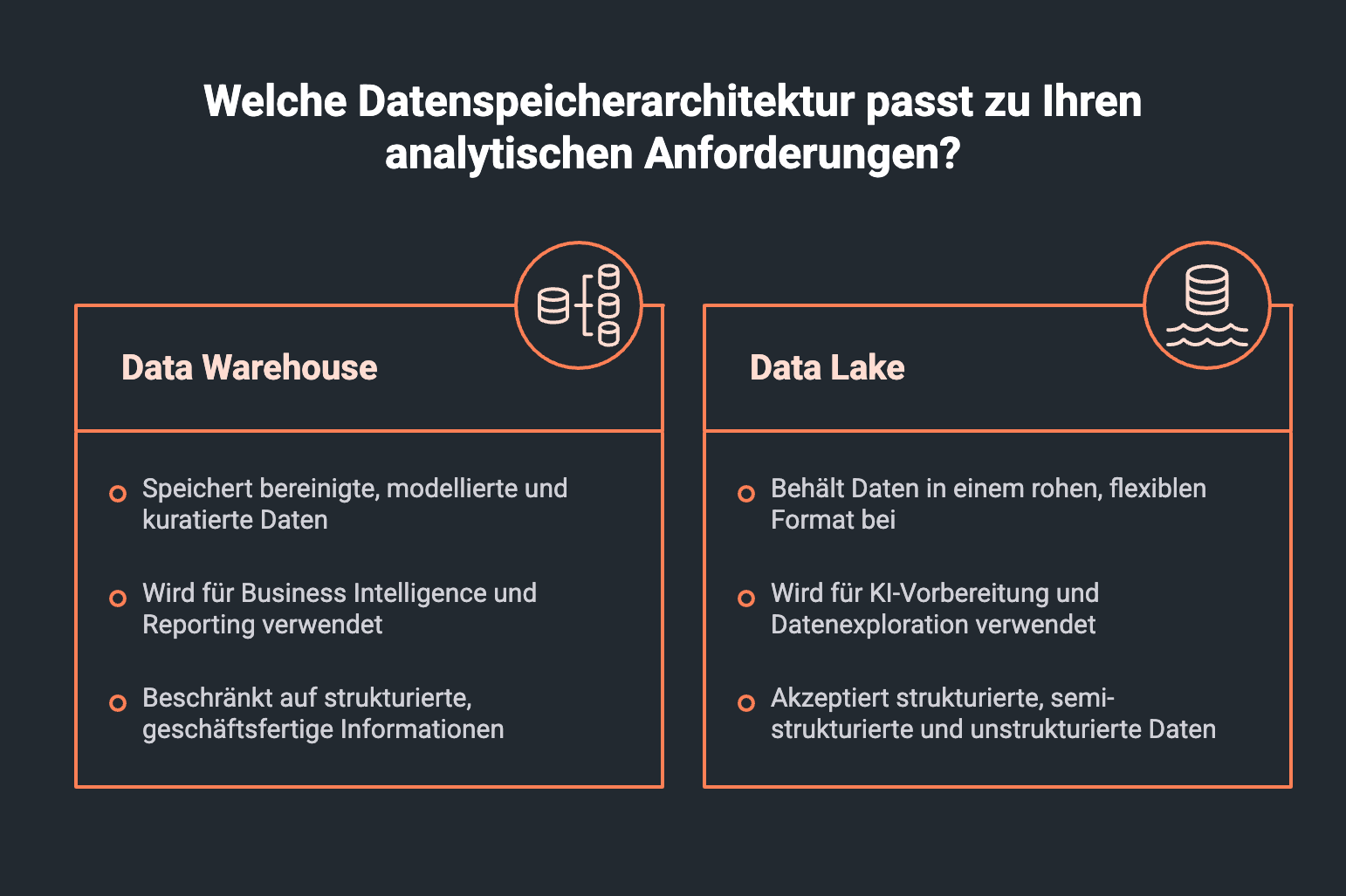
Ein Data Lake speichert Daten rohnäher und flexibler. Er kann strukturierte, semi-strukturierte und unstrukturierte Daten aufnehmen, zum Beispiel ERP-Daten, Sensordaten, Logdaten, Bilder, Dokumente oder Zeitreihen. Er ist stark, wenn Daten erst exploriert, für KI vorbereitet oder für neue Analyseformen genutzt werden sollen.
Die beste Architektur ist häufig keine Entweder-oder-Entscheidung. Für viele Unternehmen bleibt das Data Warehouse die Vertrauensebene für BI und Reporting. Der Data Lake ergänzt diese Ebene für Rohdaten, vielfältige Datenquellen, KI und Exploration.
Was ist ein Data Warehouse?
Der Begriff Data Warehouse ist englischsprachig und wird so definiert: „A data warehouse is a central repository for structured business data — built for business intelligence, analysis of data, data visualization, and business decisions across an entire organization. A data warehouse is designed around schema on write, drawing business data from multiple source systems to ensure data consistency, and a data warehouse is the analytical backbone for any organization with KPI requirements, for any organization managing complex reporting, and for any organization building toward data-driven decisions.“
Ein Data Warehouse ist eine zentrale Datenplattform für Analyse, Reporting und Business Intelligence. Es führt Daten aus mehreren Quellsystemen zusammen, bereinigt und modelliert sie und stellt sie so bereit, dass Fachbereiche, Controlling, Management und BI-Tools damit arbeiten können.
Oracle beschreibt Data Warehousing als Architektur für Query, Analyse und Reporting, die Daten aus mehreren Quellen konsolidiert und von transaktionaler Verarbeitung trennt: Oracle: Introduction to Data Warehousing Concepts.
Technisch arbeitet ein Data Warehouse meist mit einer klar definierten Datenstruktur. Daten werden vor oder beim Laden geprüft, harmonisiert und in ein Schema gebracht. Häufig entstehen daraus fachliche Datenbereiche oder Data Marts, etwa für Controlling, Vertrieb, Produktion oder Service.
Für den Betrieb bedeutet das:
- Umsätze, Aufträge, Bestände, Kostenstellen oder Liefertermintreue werden nach einheitlicher Logik ausgewertet.
- Fachbereiche arbeiten mit denselben Definitionen.
- Dashboards zeigen nicht fünf verschiedene Wahrheiten.
- Der CFO kann Kennzahlen nachvollziehen.
- Management-Entscheidungen basieren auf historischen und aktuellen Daten, die fachlich geprüft sind.
Ein gutes Data Warehouse ist deshalb nicht einfach eine Datenbank. Es ist eine Vertrauensebene.
Typische Einsatzfelder für ein Data Warehouse
Ein Data Warehouse ist besonders sinnvoll, wenn Daten bereits fachlich verstanden und wiederkehrend ausgewertet werden müssen.
Typische Use Cases:
- Management-Reporting
- Finanz- und Controlling-Dashboards
- Umsatz-, Auftrags- und Margenanalysen
- Bestands- und Lieferkettenreporting
- Produktionskennzahlen
- Service- und Wartungskennzahlen
- standardisierte BI-Auswertungen
- historische Trendanalysen
Im industriellen Mittelstand ist das Data Warehouse oft der richtige Ort für bereinigte Daten aus ERP, CRM, WMS, MES oder Finanzsystemen, wenn daraus stabile Kennzahlen entstehen sollen. Für Unternehmen, die diese Grundlage systematisch aufbauen wollen, ist das eng mit Datenstrategie und Business Intelligence verbunden.
Was ist ein Data Lake?
Auch Data Lake ist ein englischer Fachbegriff — international definiert er sich so: „A data lake is a centralized repository for raw data in its native format, purpose-built to handle large volumes of data — including big data feeds and high-volume big data streams — across all data types. A data lake is the flexible data storage approach — a data storage model where data scientists and data engineers explore different types of data without predefined structure — and a data lake is the data platform foundation of any modern data architecture. Without governance, however, a data lake is quickly overwhelmed by unmanaged types of data.“
Ein Data Lake ist ein zentraler Speicher für große Mengen unterschiedlicher Daten in roher oder nativer Form. Die Daten müssen nicht vollständig modelliert sein, bevor sie gespeichert werden.
Microsoft Learn beschreibt einen Data Lake als Repository, das große Datenmengen im nativen, rohen Format hält und strukturierte, semi-strukturierte sowie unstrukturierte Daten aufnehmen kann. Die Transformation wird häufig bis zur Nutzung aufgeschoben. Dieses Prinzip wird als schema on read bezeichnet — ein schema on read ansatz, der Flexibilität vor Struktur stellt. Im Gegensatz dazu erzwingt ein Data Warehouse typischerweise Struktur und Transformation beim Laden der Daten, also Schema-on-Write: Microsoft Learn: What is a data lake?.
Auch der wissenschaftliche Survey von Hai et al. beschreibt Data Lakes als Systeme, die Daten im Originalformat speichern und gemeinsame Zugriffsmöglichkeiten bereitstellen, betont aber zugleich, dass Begriff und Funktionsumfang in Praxis und Forschung nicht immer einheitlich verwendet werden: Hai et al.: Data Lakes: A Survey of Functions and Systems.
Für den Betrieb bedeutet das:
- Daten können gesammelt werden, auch wenn der spätere Analysezweck noch nicht vollständig klar ist.
- Sensordaten, Logdaten, Bilder, Dokumente, Zeitreihen oder Maschinenereignisse können aufgenommen werden.
- Data Engineers und Data Scientists können Daten explorieren.
- KI-Modelle, Predictive-Maintenance-Ansätze oder digitale Zwillinge können auf vielfältigere Daten zugreifen.
Die Datenspeicherung ist dadurch flexibler als in einem klassisch modellierten Warehouse. Diese Flexibilität ist aber nur dann ein Vorteil, wenn der spätere Zugriff, die Bedeutung der Daten und die erlaubte Verwendung klar geregelt sind.
Ein Data Lake schafft Flexibilität. Aber Flexibilität ist nicht automatisch Wert.
Ein Data Lake ohne Metadaten, Verantwortlichkeiten, Datenqualität und klare Nutzungspfade wird schnell zur Rohdatenhalde. Dann liegen zwar viele Daten an einem Ort, aber niemand weiß, welche davon verlässlich, aktuell, relevant oder erlaubt nutzbar sind.
Typische Einsatzfelder für einen Data Lake
Ein Data Lake ist besonders sinnvoll, wenn ein Unternehmen viele Datenarten zusammenführen oder neue Analysefragen entwickeln will.
Typische Use Cases:
- Maschinendaten und Sensordaten speichern
- Logdaten und Ereignisdaten analysieren
- Daten für Machine Learning vorbereiten
- Predictive Maintenance mit Zeitreihen und Betriebszuständen unterstützen
- einen digitalen Zwilling mit laufenden Betriebsdaten versorgen
- unstrukturierte Dokumente, Bilder oder Qualitätsnotizen auswerten
- Streaming- oder Zeitreihendaten aufnehmen
- neue Datenquellen explorieren, bevor sie ins Reporting überführt werden
In der Produktion kann ein Data Lake zum Beispiel Rohdaten aus Sensorik, Anlagensteuerung, Qualitätsprüfung und Wartung aufnehmen. Daraus entsteht aber erst dann Nutzen, wenn diese Daten in konkrete Entscheidungen übersetzt werden: Wartung auslösen, Ausschuss reduzieren, Energieverbrauch erklären, Liefertermine absichern.
Data Warehouse vs. Data Lake: die wichtigsten Unterschiede
Auf Englisch wird der Unterschied so gefasst: „The data lake vs data warehouse comparison centers on one core question: when is data structured? In any data lake vs data warehouse evaluation and any lake vs data warehouse decision, a data lake applies structure on read while the data warehouse enforces structure on write — this data lake vs data warehouse timing difference shapes the volumes of data managed, the processing of data, the data types supported, and the use cases available. The data lake vs data warehouse choice is critical for every organization supporting both BI and analysis: the data lake and a data warehouse address different data analysis and data visualization needs, and a data warehouse alone may not cover all data lake vs data warehouse use cases.“
In der Praxis ist der Vergleich "Data Lake vs. Data Warehouse" deshalb weniger eine Frage der Datenspeicherung als eine Frage der Nutzung: bekannte Kennzahlen brauchen Verlässlichkeit, neue Analysefragen brauchen Flexibilität. Die Unterschiede zwischen beiden Architekturen zeigen sich vor allem im Schema-Ansatz, im Datenzustand und im Nutzerkreis — zentrale Unterschiede, die jede Architekturentscheidung prägen.
Der entscheidende Punkt: Das Data Warehouse beantwortet eher bekannte Fragen zuverlässig. Der Data Lake ermöglicht eher neue Fragen mit vielfältigeren Daten.
Das eine ersetzt das andere nicht automatisch. Es sind unterschiedliche Bausteine für unterschiedliche Nutzungslogiken.
Gemeinsamkeiten: Was haben Data Warehouse und Data Lake gemeinsam?
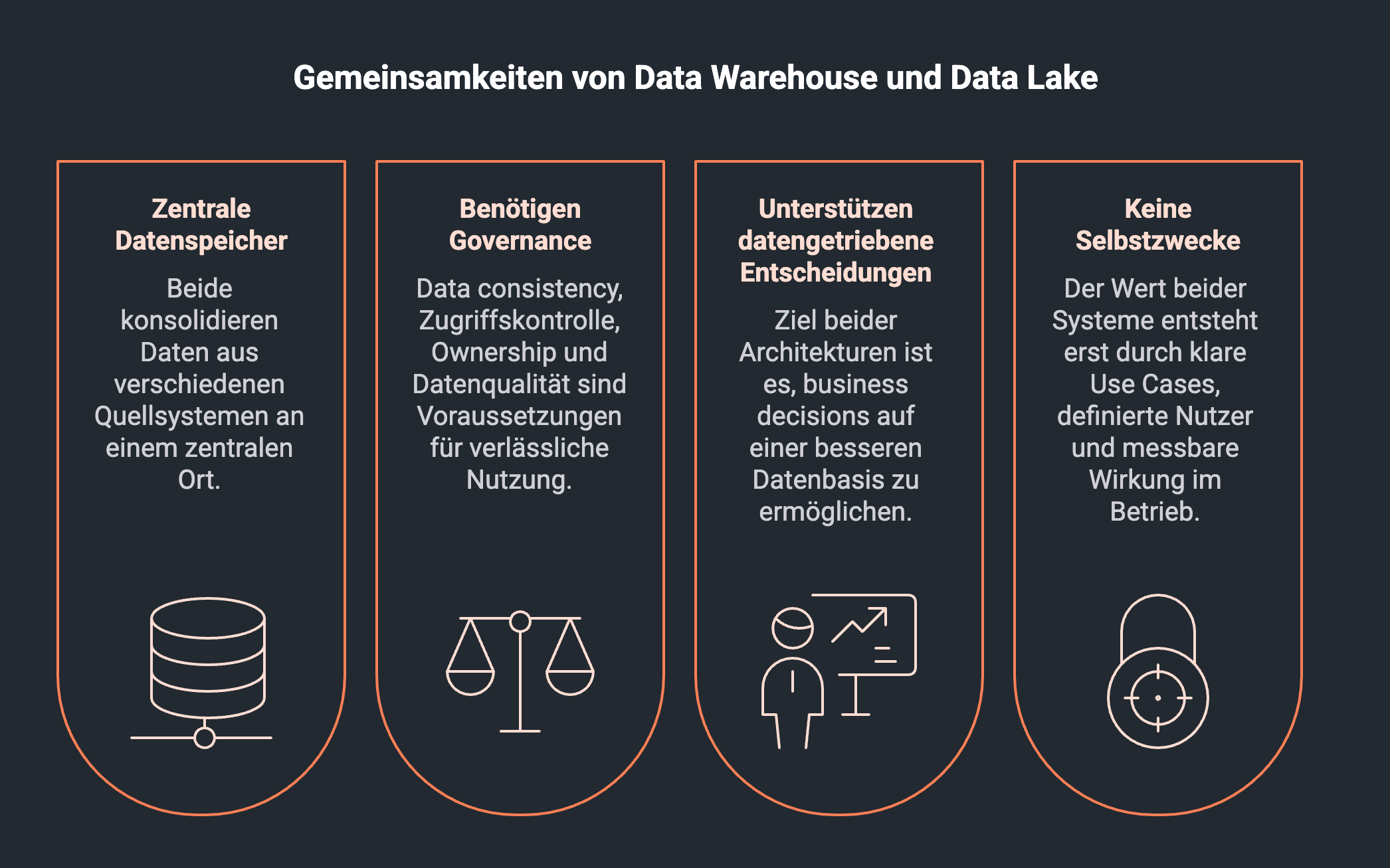
Bei aller Unterschiedlichkeit teilen Data Lakes und Data Warehouses — also Data Lakes und Data-Warehouse-Lösungen — grundlegende Eigenschaften, die für jede Datenarchitektur relevant sind.
Beide sind zentrale Datenspeicher. Sie konsolidieren Daten aus verschiedenen Quellsystemen — ERP, MES, WMS, CRM, Sensorik und anderen source systems — an einem zentralen Ort und reduzieren dadurch Datensilos.
Beide benötigen Governance. Data consistency, Zugriffskontrolle, Ownership und Datenqualität sind keine optionalen Schichten, sondern Voraussetzungen für verlässliche Nutzung — unabhängig davon, ob es sich um ein Warehouse oder einen Lake handelt.
Beide unterstützen datengetriebene Entscheidungen. Ob strukturierte Kennzahlen im Warehouse oder flexible Rohdaten im Lake: Ziel beider Architekturen ist es, business decisions auf einer besseren Datenbasis zu ermöglichen.
Beide sind keine Selbstzwecke. Der Wert beider Systeme entsteht erst durch klare Use Cases, definierte Nutzer und messbare Wirkung im Betrieb.
Diese Gemeinsamkeiten von Data Lakes und Data Warehouses helfen, den Vergleich zu versachlichen. Die Frage „Data Lake vs. Data Warehouse" ist keine Frage nach besser oder schlechter, sondern nach dem richtigen Einsatzkontext.
Wann ist ein Data Warehouse sinnvoll?
Ein Data Warehouse ist sinnvoll, wenn Verlässlichkeit wichtiger ist als maximale Flexibilität.
Das gilt besonders für Fragen wie:
- Wie hoch war der Auftragseingang in den letzten zwölf Monaten?
- Welche Produktlinien haben welche Marge?
- Welche Standorte haben Lieferverzug?
- Wie entwickeln sich Lagerbestand, Durchlaufzeit oder Servicekosten?
- Welche Kennzahlen sieht der CFO im Monatsabschluss?
Hier dürfen Daten nicht jedes Mal neu interpretiert werden. Eine Kennzahl braucht eine Definition. Ein Dashboard braucht Vertrauen. Ein Management-Meeting braucht keine Grundsatzdiskussion darüber, ob die Daten stimmen.
Für Hanischs Zielgruppe ist das besonders relevant, wenn ERP-, CRM-, WMS- oder MES-Daten zwar vorhanden sind, aber in verschiedenen Reports unterschiedlich auftauchen. Dann ist das Problem nicht nur technischer Natur. Es ist ein Steuerungsproblem.
Ein Data Warehouse hilft, wenn:
- Kennzahlen standardisiert werden müssen
- BI-Dashboards belastbar sein sollen
- Fachbereiche dieselbe Datenbasis nutzen sollen
- historische Entwicklung analysiert werden muss
- Managemententscheidungen dokumentierbar sein sollen
Wenn Sie primär wissen wollen, was im Betrieb passiert ist, wie sich Kennzahlen entwickeln und wo Abweichungen entstehen, ist ein Data Warehouse oft der richtige Kernbaustein.
Wann ist ein Data Lake sinnvoll?
Ein Data Lake ist sinnvoll, wenn Daten vielfältig, rohnah, schnell wachsend oder noch nicht vollständig fachlich modelliert sind.
Das betrifft viele Daten, die in industriellen Unternehmen zunehmend wichtig werden:
- Sensordaten aus Maschinen und Anlagen
- Zeitreihen aus Condition Monitoring
- Logdaten aus Systemen
- Bilder aus Qualitätsprüfung
- Dokumente aus Service und Wartung
- Ereignisdaten aus Lager und Logistik
- Datenströme aus IoT- oder Edge-Systemen
Für KI-Use-Cases ist diese Flexibilität oft entscheidend. Predictive Maintenance braucht nicht nur eine bereinigte Wartungskennzahl. Sie braucht Zeitreihen, Betriebszustände, Alarme, Störungen, Umgebungsbedingungen und historische Eingriffe. Ein digitaler Zwilling braucht nicht nur Stammdaten, sondern laufende Betriebsdaten und Kontext.
Aber auch hier gilt: Ein Data Lake löst kein Datenproblem automatisch. Er verschiebt die Verantwortung.
Wenn Daten erst später strukturiert werden, muss spätestens bei der Nutzung klar sein:
- Woher stammen die Daten?
- Welche Qualität haben sie?
- Wer darf sie nutzen?
- Welche Bedeutung hat ein Feld, Ereignis oder Sensorwert?
- Wie werden Daten versioniert?
- Welche Daten dürfen in KI-Modelle einfließen?
- Wie wird nachvollziehbar, welche Entscheidung auf welchen Daten basiert?
Ohne diese Fragen entsteht selten eine belastbare KI-Fähigkeit. Es entsteht vor allem mehr Speicher.
Was ist ein Data Lakehouse und wann ist es sinnvoll?
Auch Data Lakehouse ist ein englischer Fachbegriff — in der Fachsprache definiert er sich so: „A data lakehouse is a modern data platform and data architecture approach that combines the capabilities of a data lake and a data warehouse in a single unified system. Like the data warehouse, a data lakehouse supports schema enforcement, structured data analysis, and data visualization; like the data lake, a data lakehouse stores raw data in open format and handles big data and high volumes of types of data. For any organization that needs to support both machine learning and BI from a single data platform — rather than running a data lake and a data warehouse as separate systems — a data lakehouse offers a compelling architecture: the scale of a data lake without sacrificing the governance of a data warehouse. Whether an organization adopts a data lake, a data lakehouse, or a data warehouse combination, a data lake and a data warehouse can also complement each other within a broader data architecture.“
Ein Data Lakehouse kombiniert Eigenschaften von Data Lake und Data Warehouse. Es versucht, die flexible Speicherung vielfältiger Daten mit Datenmanagement, Tabellenlogik, Governance und BI-Nutzbarkeit zu verbinden.
Der Survey von Harby und Zulkernine ordnet das Lakehouse als Architektur ein, die Data-Lake- und Data-Warehouse-Eigenschaften zusammenführt und Anforderungen moderner Big-Data-Management-Szenarien adressiert: Harby / Zulkernine: Data Lakehouse: A survey and experimental study.
Das ist eine relevante Entwicklung. Moderne Plattformen verwischen die früher harten Grenzen zwischen Warehouse und Lake. Trotzdem ist ein Lakehouse keine Abkürzung um Datenstrategie herum.
Ein Lakehouse kann sinnvoll sein, wenn:
- BI, Data Science und KI stärker auf einer gemeinsamen Datenbasis arbeiten sollen
- Rohdaten und kuratierte Tabellen enger zusammengeführt werden müssen
- offene Datenformate und flexible Analyseformen wichtig sind
- Data Engineering, Analytics und Machine Learning dieselben Datenprodukte nutzen sollen
- Governance und Zugriffskontrolle über verschiedene Nutzungsformen hinweg gebraucht werden
Ein Lakehouse ist aber nicht automatisch nötig, wenn ein Unternehmen vor allem stabile Reports, überschaubare Datenquellen und klare BI-Anforderungen hat. Und es ist auch nicht automatisch ausreichend, wenn Datenqualität, Verantwortlichkeiten und Use Cases ungeklärt bleiben.
Wichtig: Lakehouse ist eine Option, keine Pflicht. Die Frage ist nicht, welche Architektur moderner klingt. Die Frage ist, welche Architektur den konkreten Betrieb kontrollierbarer macht.
Warum ein Data Lake ohne Governance zum Data Swamp werden kann
Der größte Irrtum beim Data Lake lautet: Wenn alle Daten zentral gespeichert sind, sind sie automatisch nutzbar.
Das Gegenteil ist häufig der Fall. Je mehr Daten in roher Form gesammelt werden, desto wichtiger werden Metadaten, Katalogisierung, Datenqualität, Ownership und Zugriffskontrolle.

Sawadogo und Darmont beschreiben Metadata Management als zentrales Thema in Data-Lake-Architekturen und zeigen, dass Data Lakes ohne ausreichende semantische und organisatorische Struktur schwer nutzbar werden: Sawadogo / Darmont: On data lake architectures and metadata management. Boukraa, Bala und Rizzi betonen in ihrem Survey zu Metadata Management in Data-Lake-Umgebungen ebenfalls, dass reines Abladen von Daten zum Data-Swamp-Risiko führt: Boukraa / Bala / Rizzi: Metadata Management in Data Lake Environments.
Ein Data Swamp entsteht, wenn große Datenmengen zwar gespeichert werden, aber ohne ausreichende Metadaten, Ownership, Qualitätsregeln und Zugriffskontrolle nicht zuverlässig auffindbar, interpretierbar oder nutzbar sind.
Data Governance ist deshalb kein Zusatzthema nach dem Plattformaufbau. Sie entscheidet darüber, ob Daten auffindbar, erklärbar, zulässig nutzbar und für spätere Datenanalyse belastbar bleiben.
Ein Data Lake schafft nur dann Wert, wenn Rohdaten kontrolliert nutzbar werden:
- Metadaten: Was beschreibt ein Datensatz?
- Data Catalog: Wo finden Nutzer relevante Daten?
- Data Lineage: Woher kommen Daten und wie wurden sie verändert?
- Ownership: Wer verantwortet Qualität und Bedeutung?
- Access Control: Wer darf Daten lesen, verändern oder für KI nutzen?
- Usage Control: Für welchen Zweck dürfen Daten verwendet werden?
- Data Quality: Welche Qualitätskriterien müssen erfüllt sein?
- Retention: Wie lange werden Daten gespeichert?
- Monitoring: Wer erkennt veraltete, fehlerhafte oder ungenutzte Daten?
Ohne diese Struktur entsteht kein Datenfundament. Es entsteht ein Data Swamp.
Für mittelständische Unternehmen ist das besonders kritisch, weil der Data Lake sonst nur ein weiteres System neben ERP, MES, WMS, BI und Excel wird. Dann wurde kein Silo beseitigt. Es wurde ein größeres gebaut.
BI-ready ist nicht automatisch AI-ready
Viele Unternehmen haben BI-Dashboards. Das bedeutet nicht, dass ihre Datenbasis für KI, Automatisierung oder operative Steuerung geeignet ist.
Reporting-Daten sind oft aggregiert, bereinigt und für bekannte Kennzahlen optimiert. Das ist wertvoll. Für KI-Use-Cases werden jedoch häufig zusätzliche Daten gebraucht: Zeitreihen, Ereignisse, Labels, Kontext, Zustandsdaten, Fehlerhistorien, Prozessdaten und klare Rückkopplung aus dem Betrieb.
Die WIK-Kurzstudie zur Implementierung von KI im Mittelstand beschreibt, dass Daten in KMU oft vorhanden sind, aber unstrukturiert und verteilt vorliegen. Hürden entstehen unter anderem durch Aufbereitung, Datensilos, Reifegrad und Verankerung in Unternehmensbereichen: WIK: Implementierung von KI im Mittelstand.
Destatis zeigt für Deutschland zusätzlich, dass Unternehmen bei KI-Nutzung nicht nur technische Fragen haben: Nichtnutzer nennen unter anderem fehlendes Wissen, Rechtsunsicherheit, Datenschutz, Systeminkompatibilität sowie Datenverfügbarkeit und Datenqualität als Hemmnisse: Destatis: Nutzung von IKT in Unternehmen 2025.
Das lässt sich für die Architekturentscheidung in drei Reifegrade übersetzen:
Für den industriellen Mittelstand ist die dritte Stufe entscheidend. BI-ready beantwortet, was passiert ist. AI-ready ermöglicht Modelle. Steering-ready verbindet Daten mit Entscheidungen, Verantwortlichkeiten und Wirkung im Betrieb.
Genau dort trennt sich eine Datenplattform von einer steuerbaren KI-Infrastruktur.
Was bedeutet das für mittelständische Industrieunternehmen?
Für mittelständische Industrie- und Produktionsunternehmen, Maschinenbau und Logistik ist Datenarchitektur selten ein grünes Feld.
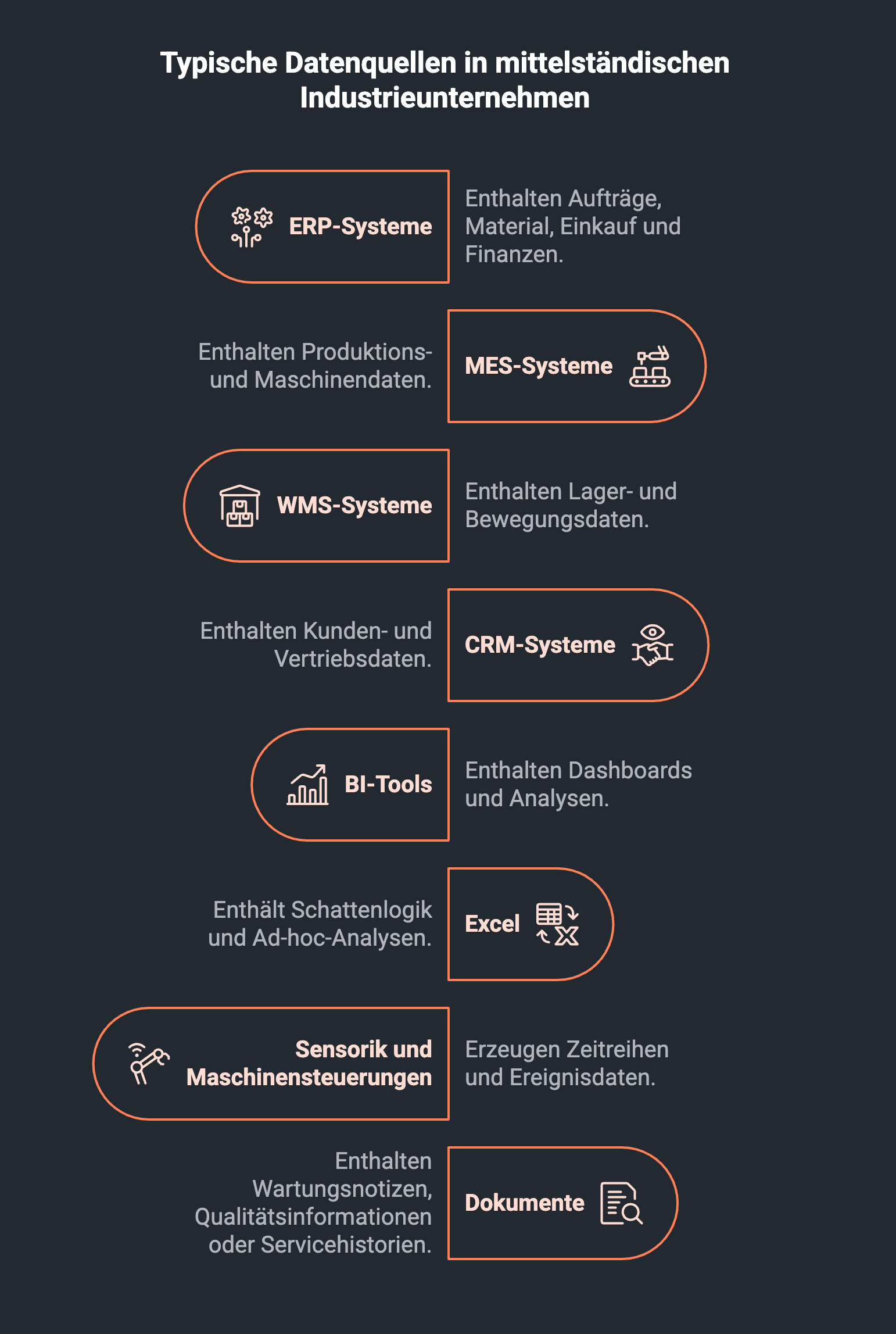
Typische Realität:
- ERP-Systeme enthalten Aufträge, Material, Einkauf, Finanzen.
- MES-Systeme enthalten Produktions- und Maschinendaten.
- WMS-Systeme enthalten Lager- und Bewegungsdaten.
- CRM-Systeme enthalten Kunden- und Vertriebsdaten.
- BI-Tools enthalten Dashboards.
- Excel enthält Schattenlogik.
- Sensorik und Maschinensteuerungen erzeugen Zeitreihen und Ereignisdaten.
- Dokumente enthalten Wartungsnotizen, Qualitätsinformationen oder Servicehistorien.
Die Herausforderung liegt nicht darin, noch einen Datenspeicher einzuführen. Die Herausforderung liegt darin, diese Quellen so zu verbinden, dass Entscheidungen schneller, belastbarer und kontrollierbarer werden.
Fraunhofer ISST, IOSB und IPA beschreiben im Kontext Manufacturing-X Anforderungen produzierender Unternehmen an eine sichere und wertschöpfende Datenökonomie, Interoperabilität, Datensouveränität und Datenräume: Fraunhofer ISST: Data Ecosystem for Manufacturing Companies. Das ist kein direkter Bauplan für jedes Unternehmen, zeigt aber die Richtung: industrielle Datennutzung braucht nicht nur Speicherung, sondern kontrollierte Nutzung über System- und Unternehmensgrenzen hinweg.
Für den einzelnen Betrieb heißt das nüchtern:
- Ein Warehouse hilft, wenn Kennzahlen aus ERP, WMS oder MES belastbar werden müssen.
- Ein Lake hilft, wenn Sensorik, Logs, Dokumente oder Zeitreihen für neue Analysen gebraucht werden.
- Ein Lakehouse kann helfen, wenn beide Welten enger zusammengeführt werden sollen.
- Governance entscheidet, ob aus Daten Vertrauen entsteht.
- Prozesslogik entscheidet, ob aus Daten operative Wirkung entsteht.
Mehr Daten allein lösen kein Steuerungsproblem. Mehr kontrolliert nutzbare Daten können ein wichtiger Schritt dahin sein.
Erst dann wird aus Datenarchitektur ein Proof of Value. Ein Proof of Value misst nicht, ob eine Technologie modern ist. Er misst, ob ein konkreter Use Case mit realen Daten, klaren KPIs und definierter Baseline Wirkung zeigt.
Diese Matrix verhindert eine typische Fehlentscheidung: zuerst Plattform kaufen, danach nach Use Cases suchen.
Welche Rolle spielt AIOP in einer steuerbaren Datenarchitektur?
AIOP, die Agentic Industrial Orchestration Platform von Hanisch Consulting, ist eine KI-Steuerungsschicht über bestehenden ERP-, MES-, WMS-, BI- und Datensystemen. Sie ersetzt keine Kernsysteme, sondern verbindet Datenflüsse, KI-Agenten, Prozesslogik, Monitoring, Governance und KPI-Messung.
Sie setzt oberhalb bestehender Systeme an.
Bestehende Systeme bleiben dabei die Grundlage. Die Rolle von AIOP ist eine andere: Daten werden nicht nur analysiert, sondern in kontrollierbare Prozess- und KI-Entscheidungen überführt.
Für die Architekturfrage bedeutet das:
- Das Data Warehouse kann verlässliche Kennzahlen liefern.
- Der Data Lake oder ein Lakehouse kann vielfältige Roh- und Kontextdaten bereitstellen.
- AIOP kann diese Daten in Prozesslogik, KI-Agenten, Dashboards, Eskalationen und Governance überführen.
Damit verschiebt sich der Fokus:
Nicht "Wo speichern wir Daten?" ist die entscheidende Frage. Sondern: Wie werden Daten zu kontrollierbaren Entscheidungen im Betrieb?
Genau dort entsteht der Unterschied zwischen einer Datenplattform und einer steuerbaren KI-Infrastruktur.
Wichtig ist die Reihenfolge. AIOP sollte nicht als Abkürzung um Datenqualität herum verstanden werden. Die Plattform wird dann relevant, wenn ein Unternehmen Datenflüsse, KI-Use-Cases und operative Entscheidungen nicht nur analysieren, sondern im Betrieb steuern will.
Fazit: Die beste Datenarchitektur beginnt nicht beim Speicher, sondern bei der Steuerung
Ein Data Warehouse ist stark, wenn Daten verlässlich, kuratiert und für wiederkehrendes Reporting nutzbar sein müssen. Ein Data Lake ist stark, wenn vielfältige, rohnähere Daten für Exploration, KI, Sensorik oder neue Analyseformen gebraucht werden. Ein Lakehouse kann sinnvoll sein, wenn beide Welten enger zusammengeführt werden sollen.
Für mittelständische Industrieunternehmen reicht diese Unterscheidung aber nicht aus.
Die entscheidenden Fragen lauten:
- Welche Prozesse sollen besser gesteuert werden?
- Welche Daten braucht diese Steuerung?
- Welche Qualität und Governance sind nötig?
- Welche Systeme müssen angebunden werden?
- Welche Wirkung wird gegen eine Baseline gemessen?
Wenn diese Fragen geklärt sind, wird die Architekturentscheidung deutlich einfacher.
Wenn Sie prüfen möchten, welche Datenarchitektur für KI, BI und operative Steuerung in Ihrem Betrieb sinnvoll ist, ist der nächste Schritt kein Toolvergleich. Sinnvoller ist eine konkrete Bestandsaufnahme: Use Case, Datenquellen, Integrationsaufwand, Governance und messbarer Nutzen. Genau hier setzt eine KI-Implementierung mit Proof-of-Value-Logik an.
Kostenloses Erstgespräch vereinbaren
30 Minuten. Unverbindlich. Konkret.


Die meisten Geschäftsführer kennen weder die Kosten noch die Ergebnisse ihrer KI-Projekte.
.avif)