
Das wichtigste auf einen Blick:
Condition Monitoring klingt zunächst nach Sensorik. Eine Maschine bekommt Schwingungssensoren, Temperaturmessung oder Energieüberwachung, Daten laufen in ein Dashboard, und die Instandhaltung sieht früher, wenn etwas nicht stimmt.
Das ist richtig, aber zu kurz gedacht.
Für mittelständische Industrieunternehmen entsteht der eigentliche Wert von Condition Monitoring nicht dadurch, dass mehr Daten gemessen werden. Wert entsteht erst, wenn Zustandsdaten in klare Wartungsentscheidungen, Verantwortlichkeiten, Kennzahlen, Datenarchitektur und Governance übersetzt werden.
Kurzantwort: Condition Monitoring, auf Deutsch Zustandsüberwachung, ist die kontinuierliche oder periodische Erfassung und Analyse des technischen Zustands von Maschinen, Anlagen oder Prozessen. Ziel ist es, Abweichungen vom Normalzustand frühzeitig zu erkennen, Wartung bedarfsorientierter zu planen und ungeplante Stillstände besser zu vermeiden.
Die internationale Norm ISO 17359:2018 beschreibt Condition Monitoring als Programm für Maschinen, nicht als einzelnes Gerät. Auch ISO 13374-1:2003 macht deutlich, dass zu Condition Monitoring nicht nur Messung gehört, sondern auch Datenverarbeitung, Kommunikation und Darstellung von Diagnoseinformationen.
Genau darin liegt der entscheidende Punkt: Ein Sensor ist noch kein Condition Monitoring. Ein Dashboard ist noch keine Instandhaltungsstrategie. Und ein Alarm ist noch keine bessere Entscheidung.
Was ist Condition Monitoring?
Condition Monitoring bezeichnet die systematische Überwachung des Zustands von Maschinen, Anlagen oder Prozessen. Dafür werden Zustandsdaten erfasst, analysiert und bewertet. Typische Daten sind Schwingung, Temperatur, Druck, Durchfluss, Stromaufnahme, Energieverbrauch, Ölzustand, akustische Signale oder Prozesswerte.
Im Kern beantwortet Condition Monitoring eine Frage:
Ist der aktuelle Zustand einer Maschine, Anlage oder eines Prozesses normal, kritisch oder erklärungsbedürftig?
Diese Frage kann kontinuierlich beantwortet werden, etwa über permanent installierte Sensorik. Sie kann aber auch periodisch beantwortet werden, zum Beispiel über regelmäßige Messungen, mobile Prüfgeräte oder wiederkehrende Inspektionen.
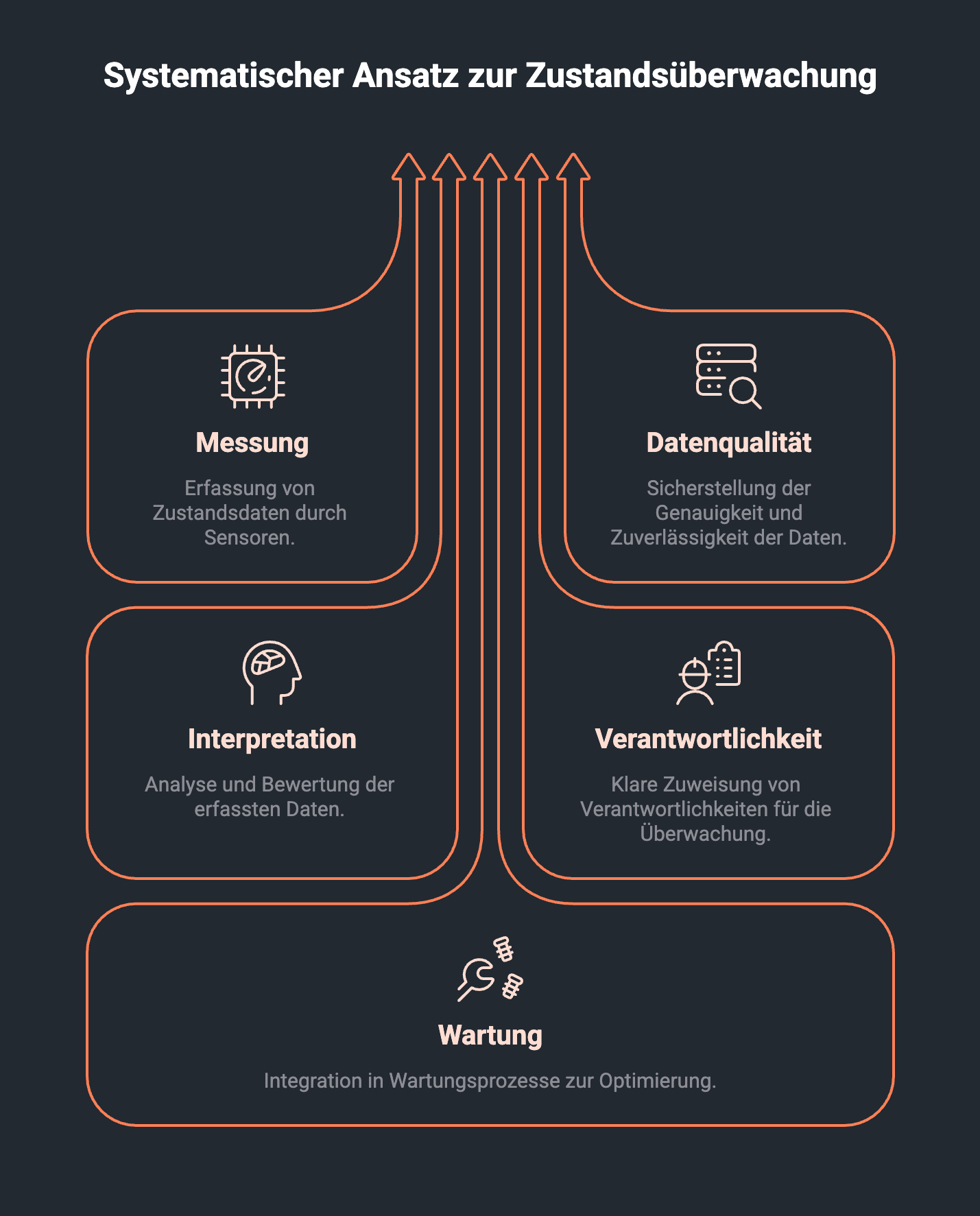
Für Entscheider ist wichtig: Condition Monitoring ist keine einzelne Technologie. Es ist ein System aus Messung, Datenqualität, Interpretation, Verantwortlichkeit und Handlung. Ein Condition Monitoring System besteht deshalb nicht nur aus Sensorik, sondern aus Datenaufnahme, Analyse, Darstellung, Verantwortlichkeit und Anschluss an Wartungsprozesse.
Ein gutes Condition Monitoring System macht Zustandsüberwachung deshalb nicht komplizierter, sondern entscheidungsfähiger: Es zeigt nicht nur Werte, sondern hilft zu verstehen, ob ein Maschinenzustand normal ist, ob eine Zustandsprüfung nötig wird und welche Rolle der Befund für Betrieb, Sicherheit und Instandhaltung spielt. So wird Zustandsüberwachung vom Messkonzept zur Grundlage steuerbarer Wartung.
Warum Condition Monitoring im Mittelstand wichtiger wird
In vielen Produktions-, Maschinenbau- und Logistikunternehmen steigt der Druck auf die Instandhaltung. Anlagen sollen länger verfügbar sein, Ersatzteile sind nicht immer sofort verfügbar, erfahrenes Maschinenwissen hängt an wenigen Personen, und ungeplante Stillstände wirken direkt auf Lieferfähigkeit, Kosten und Kundenbeziehungen.
Gleichzeitig entstehen mehr Daten als früher:
- Maschinendaten aus SPS, Steuerungen und Sensorik
- Betriebsdaten aus MES oder Produktionssystemen
- Wartungsdaten aus CMMS, Tickets, Excel oder Papierhistorie
- Qualitätsdaten aus Prüfprozessen
- Energie- und Prozessdaten aus Messsystemen
- ERP-Daten zu Ersatzteilen, Aufträgen und Kosten
Condition Monitoring wird dadurch für mittelständische Unternehmen interessanter. Nicht, weil jedes Unternehmen sofort alle Maschinen vollständig überwachen muss. Sondern weil vorhandene und neue Zustandsdaten helfen können, kritische Anlagen besser zu verstehen und Wartung planbarer zu machen.
Der beste Einstieg ist meistens nicht die Vollüberwachung des gesamten Maschinenparks. Sinnvoller ist ein fokussierter Start bei kritischen Assets: Maschinen, deren Ausfall teuer ist, deren Zustand schwer manuell zu beurteilen ist oder deren Störung ganze Prozessketten blockiert. Gerade im Maschinenbau und in Industrie und Produktion ist dieser Fokus wichtig, weil einzelne Anlagen oft ganze Wertschöpfungs- oder Lieferketten beeinflussen.
Condition Monitoring, zustandsorientierte Wartung, Predictive Maintenance und Prescriptive Maintenance im Vergleich
Condition Monitoring wird häufig mit Predictive Maintenance gleichgesetzt. Das führt zu falschen Erwartungen.
Condition Monitoring misst und bewertet aktuelle oder historische Zustandsdaten. Zustandsorientierte Wartung, international häufig Condition-Based Maintenance oder CBM genannt, nutzt diese Informationen, um Wartung auszulösen, wenn ein definierter Zustand erreicht ist. Predictive Maintenance geht weiter: Sie nutzt Zustandsdaten, Historie, Muster und Modelle, um zukünftige Ausfallrisiken oder Restlebensdauer zu prognostizieren. Prescriptive Maintenance ergänzt diese Prognose um Handlungsempfehlungen oder teilautomatisierte Maßnahmen.
Fraunhofer ITWM beschreibt die Logik ähnlich: Im Condition Monitoring von Anlagen werden kritische Ereignisse und Zustände mit hohem Verschleißpotenzial erkannt, klassifiziert und bewertet. Predictive Maintenance prognostiziert darauf aufbauend Risiken unerwünschter Betriebszustände und ermöglicht bedarfsorientierte Service- und Wartungsplanung.
Für den Mittelstand ist diese Abgrenzung wichtig. Wer sofort Predictive Maintenance verspricht, obwohl kaum Datenhistorie, Anlagenkontext oder Fehlerklassifikation existiert, überspringt eine notwendige Reifestufe.
Welche Zustandsdaten und Signale in der Praxis zählen
Die richtigen Messgrößen hängen vom Asset, vom Fehlerbild und vom Betriebszustand ab. Nicht jede Maschine braucht dieselbe Sensorik.
Fraunhofer IPA zeigt am Beispiel energetischer Anomalieerkennung, dass auch Energie- und Prozessdaten, die im Betrieb bereits anfallen, als Indikator für Prozessstabilität und Anlagengesundheit genutzt werden können. Das ist für mittelständische Unternehmen relevant: Der Einstieg muss nicht immer mit neuer Sensorik beginnen. Manchmal liegen erste Signale bereits in vorhandenen Messsystemen, SPS-Daten oder Prozessdaten.
Für einen ersten Überblick reicht oft eine einfache Zuordnung: Welche Sensoren erfassen Schwingungen, Temperatur, Druck oder Energie? Welche Geräte liefern bereits Prozessdaten? Welche Technologien unterstützen Maschinenüberwachung, Zustandsanalyse oder Prozessüberwachung in Echtzeit? Und welche Sensoren sind robust genug für die Umgebung an den jeweiligen Anlagenteilen? Wenn Sensoren Daten in Echtzeit liefern, kann Zustandsüberwachung schneller zwischen normaler Prozessvarianz und relevanter Abweichung unterscheiden.
In der Praxis wird die Bewertung des Maschinenzustandes häufig über mehrere Sensoren kombiniert. Ein Condition Monitoring System kann zum Beispiel Vibration, Temperatur, Stromaufnahme und Sensordaten aus der Steuerung zusammenführen. Dadurch wird Zustandsüberwachung nicht nur genauer, sondern auch anschlussfähiger an Wartungsarbeiten, Diagnose und Problemerkennung.
Die entscheidende Frage lautet deshalb nicht: Welche Daten können wir erfassen? Sondern:
Welche Daten zeigen zuverlässig das Fehlerbild, das wir früher erkennen wollen?
Die Condition-Monitoring-Wertkette: vom Signal zur Steuerung
Ein häufiger Fehler bei Condition Monitoring ist die Annahme, dass mehr Messwerte automatisch bessere Instandhaltung bedeuten.
Das Gegenteil kann passieren. Ohne Kontext erzeugt Monitoring viele Alarme, aber wenig Entscheidungssicherheit. Dann entstehen Datenfriedhöfe, Fehlalarme oder Dashboards, die technisch interessant sind, aber im Alltag nicht genutzt werden.
Hanisch Consulting betrachtet Condition Monitoring deshalb als Wertkette mit folgenden Elementen:
Diese Wertkette macht deutlich: Condition Monitoring ist nicht nur ein Messsystem. Es ist eine Entscheidungsarchitektur.
Die deutsche Instandhaltungslogik stützt diesen Blick. DIN 31051:2019 beschreibt die Grundmaßnahmen der Instandhaltung, während DIN EN 13306:2018 Instandhaltung nicht nur technischen Tätigkeiten zuordnet, sondern auch administrativen und managementbezogenen Bereichen. DIN EN 16646:2015 verknüpft Instandhaltung zusätzlich mit Physical Asset Management und dem strategischen Plan einer Organisation.
Für Entscheider heißt das: Zustandsdaten sind erst dann wertvoll, wenn sie mit Anlagenkritikalität, Wartungsprozessen, Verantwortlichkeiten und Kennzahlen verbunden werden.
Wann lohnt sich Condition Monitoring?
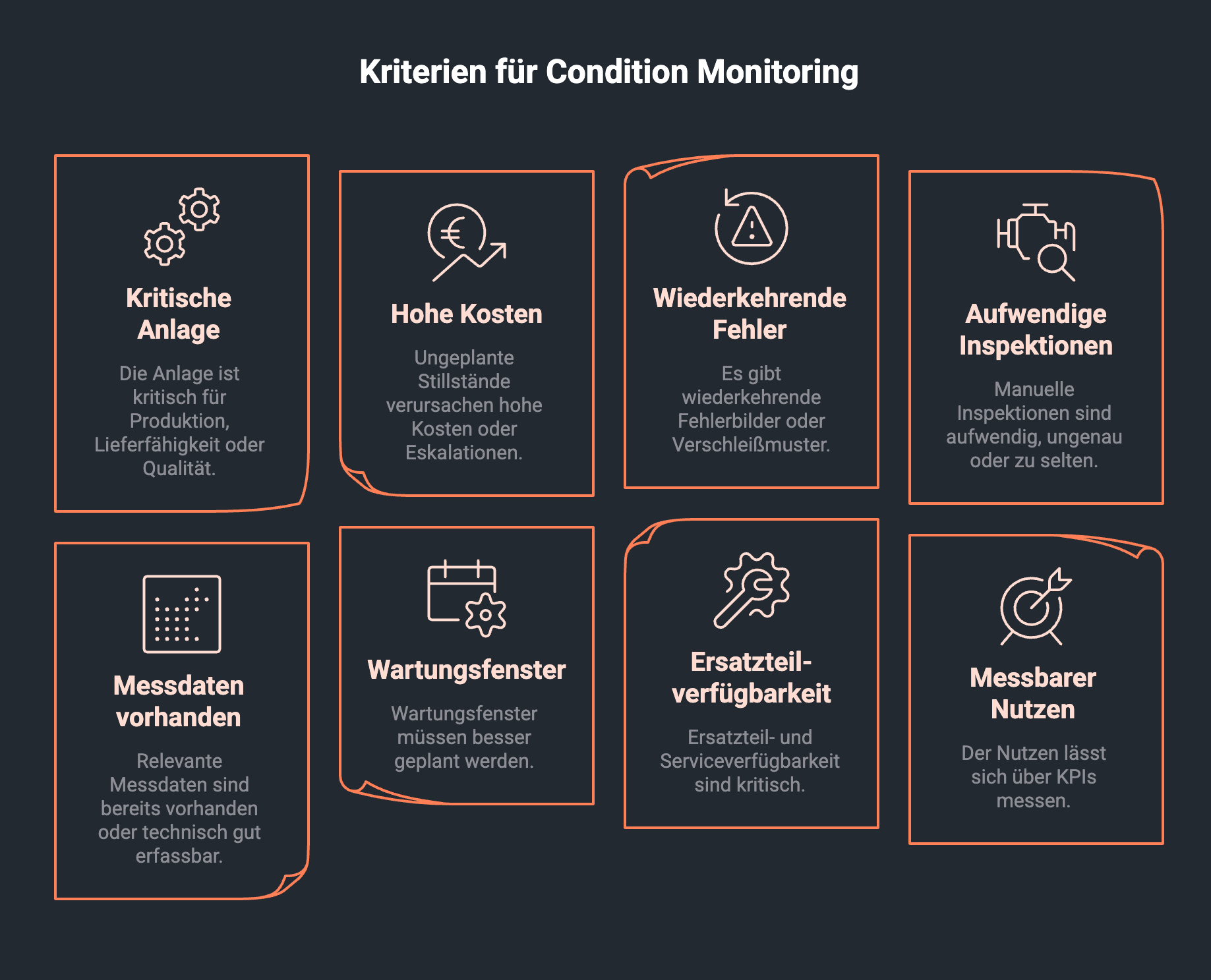
Condition Monitoring lohnt sich besonders dort, wo ein Ausfall teuer, kritisch oder schwer vorhersehbar ist. Entscheidend ist nicht die Anzahl der Sensoren, sondern der Zusammenhang zwischen Risiko, Datenbasis und Handlung.
Ein Use Case ist besonders geeignet, wenn mehrere dieser Kriterien erfüllt sind:
- Die Anlage ist kritisch für Produktion, Lieferfähigkeit oder Qualität.
- Ungeplante Stillstände verursachen hohe Kosten oder Eskalationen.
- Es gibt wiederkehrende Fehlerbilder oder Verschleißmuster.
- Manuelle Inspektionen sind aufwendig, ungenau oder zu selten.
- Relevante Messdaten sind bereits vorhanden oder technisch gut erfassbar.
- Wartungsfenster müssen besser geplant werden.
- Ersatzteil- und Serviceverfügbarkeit sind kritisch.
- Der Nutzen lässt sich über KPIs messen.
Typische KPIs sind:
- ungeplante Stillstandszeit
- Ausfallzeiten
- Anzahl kritischer Alarme
- Diagnosezeit
- Reaktionszeit der Instandhaltung
- geplante vs. ungeplante Wartung
- Wartungsarbeiten
- Ersatzteilverfügbarkeit
- Instandhaltungskosten
- Ausschuss oder Qualitätsabweichungen
- OEE oder Anlagenverfügbarkeit
- Maschineneffizienz
- MTBF und MTTR, wenn diese Kennzahlen im Unternehmen sauber geführt werden
Hanisch-Prinzip: Condition Monitoring sollte nicht mit einem pauschalen ROI-Versprechen starten. Der bessere Weg ist ein Proof of Value: eine kritische Anlage, ein klares Fehlerbild, eine Baseline und ein messbarer KPI.
Auch Fraunhofer IVI ordnet zustandsbasierte und prädiktive Wartung als Weg ein, um den Zustand kritischer Infrastrukturen oder Anlagen besser zu bewerten und Wartung gezielter zu planen. Für den Mittelstand ist daran vor allem die Logik wichtig: Erst wenn ein Fehlerbild, ein Messsignal und eine Entscheidung zusammenpassen, wird aus Monitoring ein belastbarer Use Case.
Die Vorteile entstehen also nicht automatisch durch mehr Sensoren. Sie entstehen, wenn Ausfälle, Ausfallzeiten, Instandhaltungskosten, Lebensdauer und Leistung kritischer Maschinen über eine belastbare Baseline beobachtet werden. Erst dann lässt sich beurteilen, ob ein Condition Monitoring System die richtigen Probleme adressiert und Ausfallzeiten tatsächlich besser planbar macht.
Ein zweiter Vorteil liegt in der Entwicklung von Know-how: Wenn Teams verstehen, welche Ausfälle, Auffälligkeiten und Probleme sich in welchen Signalen zeigen, werden Wartungsarbeiten planbarer und Instandhaltungskosten transparenter. Die Bewertung des Maschinenzustandes wird dann weniger von Einzelwissen abhängig.
Wie Mittelständler brownfield-tauglich starten
Viele mittelständische Unternehmen starten nicht auf der grünen Wiese. Sie haben Bestandsmaschinen, gewachsene Steuerungen, unterschiedliche Anlagenalter, vorhandene SPS-Daten, Excel-Wartungshistorien, MES-Informationen und teilweise schon Energie- oder Prozessdaten.
Deshalb sollte Condition Monitoring brownfield-tauglich geplant werden.
Der acatech Industrie 4.0 Maturity Index stützt diesen Reifegradblick: Digitale Transformation entsteht nicht nur durch Technologie, sondern durch das Zusammenspiel von Informationssystemen, Ressourcen, Organisation und Kultur. Für Condition Monitoring heißt das: Sensorik ist ein Baustein, aber nicht der Reifegrad selbst. Gerade im Industrie 4.0-Kontext entscheidet die Entwicklung von Datenflüssen, Rollen und Entscheidungsprozessen darüber, ob Monitoring skaliert.
1. Kritische Assets priorisieren
Zuerst wird geklärt, welche Maschinen oder Anlagen wirklich relevant sind. Eine Priorisierung kann nach Ausfallkosten, Prozesskritikalität, Sicherheitsrelevanz, Fehlerhistorie und Wartungsaufwand erfolgen.
2. Fehlerbild und Zielentscheidung definieren
Danach wird festgelegt, welches Problem erkannt werden soll. Geht es um Lagerverschleiß, Überhitzung, Druckabfall, Leckage, Energieabweichung, Werkzeugverschleiß oder Prozessinstabilität?
Jedes Fehlerbild braucht eine Zielentscheidung:
- früher prüfen
- Ersatzteil bestellen
- Wartungsfenster planen
- Prozessparameter anpassen
- Anlage stoppen
- menschliche Freigabe einholen
3. Vorhandene Datenquellen prüfen
Jetzt erst wird die Datenbasis geprüft. Welche Daten gibt es bereits? Welche Daten fehlen? Wie zuverlässig sind Zeitstempel, Messintervalle, Betriebszustände und Datenqualität?
Fraunhofer ITWM betont bei Predictive-Maintenance-Projekten die Bedeutung von Messqualität und Informationsgehalt. Gerade bei mittelständischen Anlagen ist es wichtig, nicht blind Daten zu sammeln, sondern die minimale Sensorik mit maximalem Informationswert zu identifizieren.
4. Sensorik gezielt ergänzen
Neue Sensorik ist sinnvoll, wenn sie eine relevante Entscheidung verbessert. Sie ist weniger sinnvoll, wenn sie nur zusätzliche Daten erzeugt, für die kein Prozess, keine Verantwortlichkeit und keine Kennzahl existiert.
5. Alarm- und Eskalationslogik definieren
Ein Alarm ohne Verantwortlichkeit ist nur Lärm. Deshalb muss klar sein:
- Wer erhält welche Meldung?
- Welche Priorität hat der Alarm?
- Welche Daten braucht die Person zur Diagnose?
- Wann wird eskaliert?
- Welche Entscheidung bleibt beim Menschen?
- Wie wird dokumentiert, was passiert ist?
6. Pilot gegen Baseline messen
Der Pilot sollte nicht beweisen, dass Daten sichtbar sind. Er sollte beweisen, dass bessere Entscheidungen entstehen.
Gute Pilotfragen:
- Wurde eine relevante Abweichung früher erkannt?
- Wurden Fehlalarme reduziert?
- Wurde Wartung besser geplant?
- Wurde Diagnosezeit verkürzt?
- Wurde ein kritischer Stillstand vermieden oder besser vorbereitet?
- Wurde eine klare Go/No-Go-Entscheidung möglich?
Wie läuft der Condition-Monitoring-Prozess ab?
Der Condition-Monitoring-Prozess ist kein reiner Datenprozess. Er verbindet Zustandserfassung, Zustandsvergleich, Diagnose, Entscheidung und Erfolgsmessung.
Praktisch heißt das: Zuerst werden kritische Maschinen und Fehlerbilder priorisiert. Danach werden passende Messgrößen, vorhandene Datenquellen und zusätzliche Sensorik geprüft. Anschließend werden Normalzustände, Grenzwerte, Anomalien, Alarmwege und Verantwortlichkeiten definiert. Am Ende muss gemessen werden, ob die Zustandsüberwachung Wartungsentscheidungen tatsächlich verbessert.
Die Datenarchitektur hinter wirtschaftlichem Condition Monitoring
Condition Monitoring wird erst skalierbar, wenn Zustandsdaten nicht in isolierten Dashboards hängen bleiben.
Typische Ebenen einer Architektur sind:
- Maschine oder Anlage
- Sensorik, SPS oder bestehende Messsysteme
- Edge-Komponente oder Datenaufnahme
- Zeitreihen- oder Datenplattform
- Analyse und Anomalieerkennung
- Dashboard, Alarm oder Wartungsworkflow
- ERP, MES, CMMS oder BI-Anbindung
- KPI- und Managementsicht
ISO 13374 zeigt, dass Datenverarbeitung, Kommunikation und Darstellung von Zustands- und Diagnoseinformationen Teil des Condition-Monitoring-Themas sind. Für mittelständische Unternehmen ist das relevant, weil der Nutzen nicht im isolierten Messwert entsteht, sondern im Fluss zwischen Maschine, Datenplattform, Wartungsprozess und Managemententscheidung.
In moderneren IT/OT-Architekturen können Standards und Konzepte wie OPC UA oder die Asset Administration Shell eine Rolle spielen. Sie sollten aber nicht als Selbstzweck eingeführt werden. Entscheidend ist, ob Zustandsdaten interoperabel, nachvollziehbar und handlungsfähig in bestehende Systeme und Prozesse fließen.
Genau hier berührt Condition Monitoring die Datenstrategie und Business Intelligence: Ohne saubere Datenflüsse, Stammdaten, Zeitreihen, Rollen und KPI-Logik bleibt Monitoring ein isoliertes Dashboard. Wenn Zustandsdaten zusätzlich mit Anlagenmodellen, Prozessdaten oder Simulationen verbunden werden, kann daraus später auch ein Digitaler Zwilling entstehen.
Welche Rolle KI bei Condition Monitoring spielt
KI erweitert Condition Monitoring vor allem dort, wo einfache Grenzwerte nicht mehr reichen.
Beispiele:
- Anomalieerkennung in Energie- oder Prozessdaten
- Mustererkennung in Schwingungsdaten
- Klassifikation von Fehlerbildern
- Prognose von Ausfallrisiken
- Restlebensdauer-Schätzung
- Priorisierung von Wartungsmaßnahmen
- Verbindung mehrerer Signale zu einem Anlagenzustand
KI ist aber nicht der erste Schritt in jedem Condition-Monitoring-Projekt. Viele Anwendungen starten sinnvoll mit klaren Messgrößen, Baselines, Trends, Grenzwerten und Verantwortlichkeiten. KI wird wertvoll, wenn mehrere Signale zusammenwirken, Betriebszustände wechseln, Muster schwer manuell zu erkennen sind oder Prognosen notwendig werden.
In internationalen Tool-Landschaften tauchen dafür häufig Begriffe wie Artificial Intelligence, Machine Learning, Data Analysis, Vibration Analysis, Failure Modes, Failures, Downtime, Process, Component oder Machines auf. Für den deutschen Mittelstand ist weniger der englische Begriff entscheidend als die Funktion dahinter: Algorithmen sollen Anomalien, Auffälligkeiten und Problemerkennung unterstützen, ohne die Diagnose oder die Entscheidung der Instandhaltung zu ersetzen.
Ein kurzer Begriffsüberblick hilft bei der Einordnung: Machine Learning erkennt Muster in historischen Daten, Algorithmen bewerten neue Signale gegen gelernte Normalzustände, und Data Analysis verbindet Messwerte mit Betriebszuständen. Bei rotierenden Maschinen kann Vibration Analysis Lager, Wellen oder andere Component-Risiken sichtbar machen. Englischsprachige Tool-Dokumentationen sprechen dabei oft von "systems", "machines", "failure modes", "failures", "downtime" oder "process".
Wichtig bleibt: Algorithmen sind nur so gut wie ihre Datenbasis. Algorithmen brauchen saubere Zeitstempel, korrekte Betriebszustände, plausible Grenzwerte und Feedback aus der Instandhaltung. Algorithmen sollten deshalb nicht isoliert bewertet werden, sondern immer im Zusammenspiel mit Sensoren, Wartungsprozessen und menschlicher Diagnose.
Machine Learning kann diese Entwicklung unterstützen, wenn genügend Historie und Feedback vorhanden sind. Dann helfen Algorithmen, Anomalien zu priorisieren, aber sie ersetzen nicht das operative Know how der Instandhaltung. Gute Algorithmen erklären nicht nur, dass ein Signal auffällig ist, sondern warum diese Auffälligkeit für eine konkrete Wartungsentscheidung relevant sein könnte.
Die Vorteile solcher Technologien liegen vor allem in der schrittweisen Entwicklung besserer Prozessüberwachung: Algorithmen verdichten viele Signale zu einem nutzbaren Lagebild, solange ihre Grenzen transparent bleiben. Solche Algorithmen sollten immer als Entscheidungshilfe verstanden werden, nicht als Ersatz für technische Verantwortung.
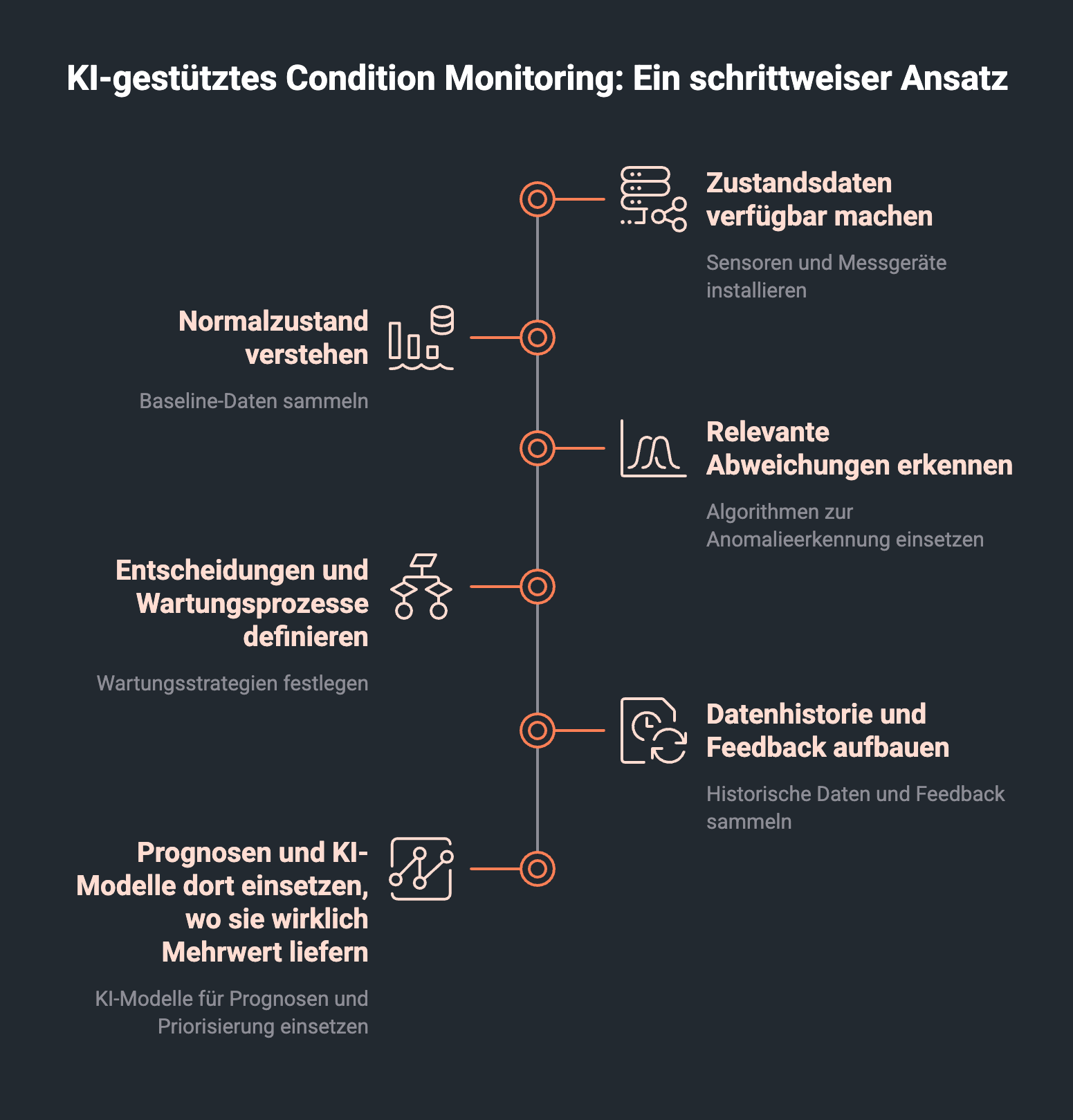
Für den Mittelstand lautet der sinnvolle Weg:
- Zustandsdaten verfügbar machen.
- Normalzustand verstehen.
- relevante Abweichungen erkennen.
- Entscheidungen und Wartungsprozesse definieren.
- Datenhistorie und Feedback aufbauen.
- Prognosen und KI-Modelle dort einsetzen, wo sie wirklich Mehrwert liefern.
Governance, Datenzugang und Verantwortlichkeiten
Condition Monitoring erzeugt nicht nur technische Fragen, sondern auch Governance-Fragen.
Entscheider sollten klären:
- Wem gehören oder wer kontrolliert Maschinendaten?
- Welche Daten dürfen intern oder extern genutzt werden?
- Welche Systeme dürfen Daten schreiben, lesen oder weitergeben?
- Wer erhält Alarme?
- Wer entscheidet bei kritischen Abweichungen?
- Wie werden Entscheidungen dokumentiert?
- Welche Daten sind für Wartungsdienstleister, OEMs oder Drittanbieter zugänglich?
Der EU Data Act ist seit dem 12. September 2025 anwendbar und stärkt den Datenzugang bei vernetzten Produkten und verbundenen Diensten. Für Unternehmen mit vernetzten Maschinen kann das langfristig relevant werden, weil Datenzugang, Drittanbieter-Wartung und industrielle Datenservices stärker geregelt werden.
Hinweis: Diese Einordnung ersetzt keine Rechtsberatung. Sie zeigt, welche Datenzugangs- und Governance-Fragen Entscheider organisatorisch prüfen sollten.
Typische Fehler bei Condition Monitoring
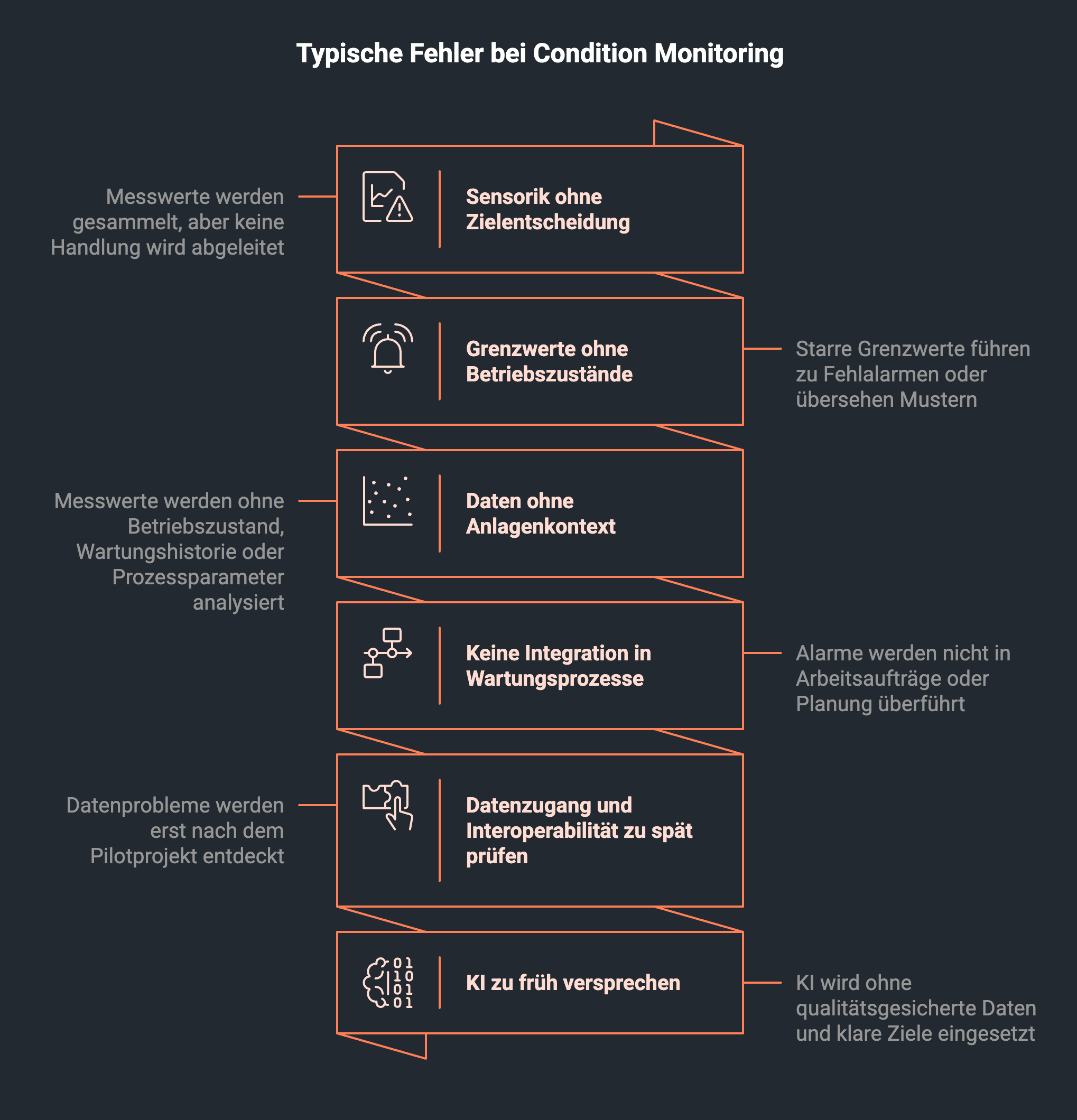
Fehler 1: Sensorik ohne Zielentscheidung
Wenn niemand weiß, welche Handlung aus einem Messwert folgen soll, wird Monitoring schnell zum technischen Nebenprojekt.
Fehler 2: Grenzwerte ohne Betriebszustände
Eine Maschine verhält sich nicht in jedem Zustand gleich. Rüstvorgänge, Lastwechsel, Materialvarianten oder saisonale Bedingungen können Messwerte verändern. Starre Grenzwerte erzeugen dann Fehlalarme oder übersehen relevante Muster.
Fehler 3: Daten ohne Anlagenkontext
Predictive Maintenance braucht nicht nur Messwerte, sondern Kontext: Betriebszustand, Wartungshistorie, Fehlerereignisse, Ersatzteile, Prozessparameter und Qualitätsdaten.
Fehler 4: Keine Integration in Wartungsprozesse
Ein Dashboard hilft wenig, wenn Alarme nicht in Arbeitsaufträge, Verantwortlichkeiten oder Planung überführt werden.
Fehler 5: Datenzugang und Interoperabilität zu spät prüfen
Wenn erst nach dem Pilot auffällt, dass Daten nicht sauber ausgelesen, geteilt oder in bestehende Systeme integriert werden können, bleibt der Use Case isoliert.
Fehler 6: KI zu früh versprechen
KI kann in Condition Monitoring sehr wertvoll sein. Aber KI braucht qualitätsgesicherte Daten, ausreichend Historie, klares Feedback und ein belastbares Ziel. Ohne diese Basis entstehen schöne Modelle, aber keine bessere Instandhaltung.
Wie Hanisch Consulting Condition Monitoring in eine steuerbare Predictive-Maintenance-Architektur überführt
Hanisch Consulting betrachtet Condition Monitoring nicht isoliert. Für mittelständische Industrieunternehmen ist entscheidend, wie Zustandsdaten in bestehende Systemlandschaften eingebettet werden: ERP, MES, WMS, BI, Excel, Sensorik, Wartungsdaten und operative Prozesse.
Genau hier setzt AIOP, die Agentic Industrial Orchestration Platform, an. AIOP ersetzt keine bestehenden ERP-, MES- oder WMS-Systeme. Die Plattform verbindet Zustandsdaten, Prozesse, Governance und KPI-Messung als Steuerungsschicht über vorhandenen Systemen.
Für Condition Monitoring bedeutet das:
- Zustandsdaten werden mit Prozess- und Geschäftskontext verbunden.
- Alarme werden nicht nur angezeigt, sondern in Workflows übersetzt.
- Wartungsentscheidungen werden dokumentierbar und auswertbar.
- Predictive-Maintenance-Use-Cases können gegen eine Baseline gemessen werden.
- Fachbereich, IT und Management erhalten ein gemeinsames Lagebild.
- Skalierungsentscheidungen werden auf Basis von Proof of Value getroffen, nicht auf Basis von Sensorik-Euphorie.
Je mehr dieser Fragen offen bleiben, desto wichtiger ist eine strukturierte Potenzialanalyse vor zusätzlicher Sensorik. Wenn mehrere Antworten unklar sind, ist der nächste sinnvolle Schritt nicht automatisch mehr Sensorik. Sinnvoller ist eine strukturierte Analyse von Use Case, Datenbasis, Integrationsaufwand und Proof of Value.
Fazit
Condition Monitoring ist eine wichtige Grundlage moderner Instandhaltung. Es macht Zustände sichtbar, erkennt Abweichungen früher und kann den Weg zu Predictive Maintenance öffnen.
Aber Zustandsüberwachung erzeugt nicht automatisch Wert.
Für mittelständische Industrieunternehmen liegt der Hebel in der Übersetzung: Messwerte müssen in Kontext, Entscheidungen, Prozesse, Verantwortlichkeiten, Datenarchitektur und KPIs überführt werden. Erst dann wird aus Monitoring eine steuerbare Instandhaltungsarchitektur.
Hanisch Consulting unterstützt Unternehmen dabei, genau diese Brücke zu bauen: von vorhandenen Maschinen- und Prozessdaten zu einem messbaren Predictive-Maintenance-Use-Case, der in bestehende Systeme integriert und gegen eine Baseline bewertet wird.
Nächster Schritt: Sie möchten prüfen, ob Condition Monitoring oder Predictive Maintenance für Ihre Anlagen sinnvoll ist? Hanisch Consulting analysiert mit Ihnen, welche kritischen Assets, Datenquellen, Integrationspunkte und KPIs für einen messbaren Proof of Value relevant wären. Kostenloses Erstgespräch vereinbaren


Die meisten Geschäftsführer kennen weder die Kosten noch die Ergebnisse ihrer KI-Projekte.
.avif)